19 i 20 maja miała miejsce w Warszawie druga edycja konferencji Atmosphere, przeznaczona dla DevOps-ów, czyli tych, których praca zawiera dwa światy: Development i Operations.
Ponoć czasy kiedy człowiek z działu Operations nigdy nie tykał się tego co Development i odwrotnie, dawno już minęły i w obliczu szybko zmieniających się technologii i konkurencji na rynku rzadko kiedy odpowiedzialności są tak podzielone.
Konferencja moim zdaniem ciekawa, chociaż nie wiem czy warta wpisowego, które w wersji 'last-minute' sięgnęło astronomicznej kwoty 1000 PLN ! Ja byłem tym szczęściarzem, któremu Michał Bartyzel udostępnił wejściówkę za darmo.
Faktem jest że organizacja konferencji była na bardzo wysokim poziomie.
Tak wyglądały przygotowania:
Super miejsce z dobrze przystosowanym audio/wideo (oczywista sprawa, gdyż było to kino), no i ciekawe tematy (2 ścieżki). Prawdopodobnie niebawem ukażą się nagrania na youtube. Na razie są tylko z poprzedniej edycji tutaj.
Zanim się ukażą postaram się kilka z nich streścić:
Dzien 1
PHIL DIBOWITZScaling systems configuration at Facebook: the paradigms, design, and software behind managing massive numbers of systems with open source and small teams
Troche o prelegencie:
![]()

Przedstawił następujące problemy w swoim teamie:
- support wielu konfiguracji z rożnych projektów
- ok. 100 000 serwerów do utrzymania
- brak centralnego miejsca przetrzymywania konfiguracji klastra
- jedna domyślna konfiguracja nadpisywana per projekt
- wiele niewielkich zespołów, każdy wprowadza swoje zmiany
- duża nadmiarowość: cześć wspólna się nie zmienia i zaciemnia wgląd w to co konkretnie się zmieniło w projekcie.
Celem było dojście do stanu gdy 4 osoby mogą utrzymać 100 000 serwerów.
Brali pod uwagę rożne narzędzia: Puppet, Chef, Spine.
W końcu wybrali Chef. Powodem była jego łatwa rozszerzalność i adaptacja do workflowu.
Osiągnęli:
- usuniecie wielu zduplikowanych plików konfiguracyjnych
- usuniecie nieużywanych settings
- stworzyli domyślną konfiguracje nadpisywaną potem w Ruby specyficznymi ustawieniami
Architektura wygląda tak, ąe jest serwer tzw. Service of Reference (SOR), który trzyma rekord węzłów w klastrze. Serwery Chef są bezstanowe, nic nie wiedza o istniejących węzłach.
Na węzłach jest zainstalowany Ohai plugin i podłączony do konkretnego SOR.
Handlery do raportów monitorują instalacje. Konfiguracje są trzymane w SVN.
Przykład:

Stworzyli tez zestaw własnych narzędzi dostępnych na githubie.
Ciekawie zapowiada się jeden z nich: test-tester - ponoć umożliwia testowanie konfiguracji bezpośrednio na serwerach produkcyjnych nie powodując dla nich zagrożenia w przypadku błędów (do końca nie zrozumiałem jak to działa).
DANIEL TOROKOur Continuous Delivery Pipeline
Daniel pracuje w Prezi
Przedstawił w jaki sposób ewoluował ich system Continuous Delivery.
Oto moje niezdarne schematy w poszczególnych fazach :) byłyby lepsze, gdyby nie jakość zdjęć z telefonu nie nadających się do niczego.
1. Każdy node monitoruje wersje uploadowaną na Amazon S3 z zainstalowaną u siebie i jeśli się zmieniła do ściąga i instaluje

Minusy: trudność w monitorowaniu procesu i utrzymaniu: każdy node konfigurowany ręcznie.
2. Dodano Zookeeper do zarządzania konfiguracjami i mission control do monitorowania

3. Lepszy monitoring Inciga (każda aplikacja ma swój health endpoint, który jest co jakiś czas sprawdzany) i parsowanie logów w Logster. Następnie statystyki są przedstawiane real-time na diagramach z użyciem Graphite i służą do analizy instalacji a także w przypadku gdy coś się wywali na produkcji.

Maximiliano jest autorem bloga http://www.mobilexweb.com/ na oraz prowadzi ranking kompatybilności przeglądarek http://mobilehtml5.org/
Developmnet aplikacji mobilnych to prawdziwa dżungla, biorąc pod uwagę różne typy aplikacji:
- natywne
- webowe
- hybrydowe
oraz mnogość urządzeń

W przypadku aplikacji webowych mamy też mnogość przeglądarek, których popularność różni się od regionu geograficznego. Z ciekawostek - rejon Indie, Pakistan, Bangladesz używa najczęściej (98%?) przeglądarki UC Browser, o której słyszałem pierwszy raz.
Nie ma jednej słusznej zasady tworzenia aplikacji mobilnych, wszystko zależy od zastosowania i docelowych użytkowników. Zawsze najważniejsza jest percepcja użytkownika, np czy użytkownikowi wydaje się że aplikacja działa wolno, czy nie. Niektóre ograniczenia urządzeń mobilnych, jak np. słabą przepustowość łącza, można zminimalizować:
- ładując zasoby, np grafikę w tle
- pre-renderując HTML po stronie serwera w zależności od rodzaju urządzenia, języka, wielkości ekranu itd.
Inne ważne zasady:
- nie frustruj użytkownika (np przy logowaniu z użyciem sieci społecznościowych nie wymagaj dostępu do wszystkich danych użytkownika jeśli tego nie potrzebujesz)
- wydajność aplikacji jako główny cel (tworzenie stron tzw. responsywnych, które dobrze renderują się na urządzeniach mobilnych ale przy okazji zasysają ogromne ilości CSS i JS to nie zawsze najlepszy pomysł, szczególnie gdy docelowa grupa prawie nigdy nie używa desktopów).
Jeśli chodzi o narzędzia i testowanie też nie jest łatwo. W zależności od platformy mamy do dyspozycji symulatory, emulatory lub urządzenie fizyczne.
Są tez strony gdzie możemy przetestować jak nasza aplikacja zachowa się na różnych urządzeniach, np.
http://developer.samsung.com/remotetestlab
Kilka wskazówek jak być przygotowanym na przyszłość i to w jakim kierunku rozwija się mobile dev.:
- technologie "push" - push z serwera na klienta
- detekcja dostępnych funkcji urządzenia (GPS, akcelerometr, itd.) i dostosowanie zachowania aplikacji do nich
- synchronizacja - śmieszny przykład jaki dał Maximiliano to gdy w środku nocy w pokoju, w którym trzyma kilkanaście różnych urządzeń mobilnych dostaje e-maila i każde z tych urządzeń dostaje "push" - nagle jego pokój zamienia się w wesołe miasteczko, wszystko gra i świeci :D
Użytkownik powinien mieć możliwość wyboru co chce na danym urządzeniu synchronizować, np gdy tableta używa do czytania prasy, książek, a telefonu do sprawdzania poczty.
Inne metodologie o których nie słyszałem wcześniej:
- RESS (Responsive Design with Server-Side components) to sposób tworzenia aplikacji klient-serwer, w którym pomiędzy klienta i serwer daje się jeszcze jedną warstwę pośrednią służącą poprawę wydajności na kliencie (np dostosowanie rozmiaru grafik do ekranu urządzenia, dostosowanie HTML, CSS, JS)
ADAM MICHALCZYKEverybody lies
Adam z Allegro zastanawiał się dlaczego ludzie kłamią, niezależnie od swojej roli w projekcie: czy to Developerzy, Product Ownerzy, Operations..
Powody bywają różne, jak:
- wygodnictwo
- wzajemne niezrozumienie
- opieranie się na opiniach, nie faktach
- strach przed konsekwencjami
Adam jest propagatorem kultury pracy, w której nie boimy się popełnić błędy o ile są one bezpieczne ("safe to fail" a nie "failsafe"), tzn istnieje cały mechanizm zabezpieczający przed tym by błędy nie były kosztowne i wychwycone wcześnie (jak np continuous integration z testami aplikacji). Powołuje się na książkę Joy Inc.
Kultura pracy nie powinna piętnować popełnianych błędów, wręcz przeciwnie - zachęcać do eksperymentowania i otwartości.
SZYMON PRZYBYLSKIOptimising and Automating your Front End Workflow
Jakich narzędzi powinien dziś używać front-end developer by ułatwić sobie życie?
Apki JavaScript-owe bardzo ewoluowały w przeciągu ostatnich kilkunastu lat. To już nie tylko język który upycha się gdzieś w stronę JSP ale pozwalający tworzyć kompletne aplikacje po stronie klienta i serwera. Narzędzia godne poznania to:
- npm
- bower
- grunt
- gulp
- walidatory: JSLint, JSHint, ESLint
- frameworki do testowania: Jasmine, Mocha, QUnit
KRZYSZTOF DEBSKILet's build a solid base for a scale.
Krzysiek pracuje w Allegro, które obchodzi w tym roku 15 rocznicę powstania. Od czasu, gdy powstało przeszło sporą ewolucję technologiczną od homogenicznego sytemu do skalowalnego w chmurze z 15 mln. użytkowników.
Obecnie architektura opiera się na mikro-serwisach komunikujących się ze sobą rożnymi API (REST, SOAP, CORBA..) Modernizacja trwa. W grę wchodzą takie technologie jak:
Zookeeper - jako rejestr serwisów
Swagger - biblioteka do generacji dokumentacji dla serwisów REST, dostepne także Swager UI, całkiem przyjemna strona HTML do wizualizacji dokumentacji.
Do tworzenia REST API używany jest Jersey, wersjonowanie REST API za pomocą HTTP nagłówka Accept.
Konfiguracja serwisu kilkustopniowa:
- Zookeeper
- zmienne środowiskowe
- argumenty linii komend
Początkowo serwisy były bootstrapowane w zewnętrznym Jetty ale działało to zbyt wolno, stąd przejście na embedded Jetty a potem na embedded Undertow. Dzięki temu każdy serwis jest samodzielny, nie potrzeba go deployować na serwerze.
Monitoring z użyciem:
- Logstash
- Kibana
- NxLog
- Graphite


Obecnie trwają eksperymenty z użyciem Dockera.
MaTeusz HarasymczukRE:SPONSIBILITY.
Ten wykład był poprowadzony w zastępstwie za Andy Hawkinsa.
Mateusz zastanawiał się nad tym po co skupiać się na poprawie jakości istniejących rozwiązań skoro klient za to nie płaci tylko za nowe funkcjonalności. Otóż warto, bo to właśnie utrzymanie kosztuje najwięcej.
Przy przejrzystym i prostym kodzie z małą liczbą zależności utrzymanie to przyjemność a jakiekolwiek zmiany są szybkie do implementacji.

MACIEJ LASYKScaling and securing node.js apps
Źródło informacji o security w node.js: https://nodesecurity.io/
Aplikacje node.js działają blisko systemu operacyjnego przez co narażone na wiele błędów związanych z bezpieczeństwem.
Co więcej, mnogość bibliotek pisanych często bez nadzoru zewnętrznej instytucji pozwala przecieknąć do naszej aplikacji potencjalnie niebezpiecznym kodom, dlatego zewnętrzne kody co do których nie jesteśmy pewni powinny być przeskanowane pod kątem użycia niebezpiecznych konstrukcji takich jak:
- eval(code)
- setInterval(code, ..)
- setTimeout(code,..)
- str = new Function(code)
- global namespace polution - gdy wszystkie zmienne w kodzie serwerowym są wspólne dla wszystkich klientów, należy o tym pamiętać, że w aplikacjach node.js wszyscy klienci używają jednej metody serwerowej, która działa w jednym wątku, dlatego też współdzielą jej zmienne.
Przykładowy błąd:
Gdy jeden klient zostaje zautentykowany, zapisujemy w globalnej zmiennej, że ma dostęp do zasobów.
Następnie serwer obsługuje request innego klienta, który jeszcze się nie logował ale ponieważ stan został zmieniony przez poprzedniego klienta, ten drugi może bezprawnie dostać się do zasobów chronionych.
- niełapane wyjątki powodujące wywalenie się głównej metody serwera i tym samym stopujące serwer (teraz już po konferencji wertując sieć natknąłem się na taką stronkę o wyjątkach w node.js)
Metody prewencji:
- strict mode ("use strict;"), również dla dołączanych bibliotek - dzięki temu parser wychwyci wszystkie metody, w których przekazywane mogą być komendy systemowe w stringu.
- JSHint (node-jshint), JSLint (node-jslint
- statyczne analizatory kodu
- retire.js
- użycie gotowych modułów do autentykacji zamiast pisać ręcznie i narażać się na błedy, np passportjs
- express-domain-middleware
- sandboxing - proces nodejs nie jest uruchamiany bezpośrednio w systemie operacyjnym ale w chronionym środowisku, które nie ma dostępu np do prawdziwego systemu plików, czyli wirtualizacja, np: SELinux Sandbox
Dzien 2
MICHAL CZAPRACKIScalability and Websockets: Creating a Websocket CDN with DIASP.
Zalety websocket:
- ciągła komunikacja
- komunikacja dwukierunkowa
- zabiera małą część łącza
- wiele bibliotek implementujących
Wady websocket:
- wiele jednocześnie otwartych połączeń
- trudne do implementacji w standardowych frameworkach
- niekompatybilne z większością proxy (np Varnish, Squid)
- brak warstwy cache
Michał brał udział w tworzeniu rozwiązania opartego na websocketach dla gazera.pl web i sport.pl web (obie około 2mln ściągnięć na urządzeniach mobilnych). Z powodu ograniczeń standardowych bibliotek websocket musieli napisać własne rozwiązanie które pozwalało na cachowanie, tzw DIASP (Diasp Is a Socket Proxy)
Testy pokazały że jest ono w stanie obsłużyć 20 000 jednoczesnych połączeń na maszynie z 300MB RAM
W dniu prezentacji rozwiązanie zostało OpenSource-owane na
https://github.com/AgoraTech/diasp
MACIEJ KUZNIARSwitching from monolithic approach to modular cloud computing, within the context of providing high availability application
Maciej opowiedział z grubsza o serwisach dostarczanych przez Octawave, czyli generalnie wszystko o czym można poczytać na https://www.oktawave.com/pl/instancje-chmury.html
DARIUSZ ELIASZCentralized log management based on Logstash and Kibana - case study.
I znów pojawiają się znajome nazwy (na razie jedynie nazwy bo nie próbowałem tego jeszcze).
Darek opowiedział o swojej drodze do stworzenia systemu zarządzania logami i monitoringu aplikacji.
Pierwszy etap to wybór właściwego protokołu komunikacji. Rozważane opcje:
- RFC 3164 - limitowany do 1KB, stały format, niezbyt elastyczny
- JSON - lekki, elastyczny, bez limitu co do formatu, duże wsparcie istniejących bibliotek i narzędzi
Architektura zbierania logów:
 Sender:
Sender:
wiele interfejsów wejściowych (ftp, tcp, udp socket), wiele rodzajów parserów (BSD log, JSON)
jak najwięcej się da przetwarzania logów robi Sender zanim pości je dalej.
W pierwszej wersji użyty był NxLog, potem zastąpiony syslog-ng
Log Router:
w pierwszej wersji Logstash + Redis, potem tylko Redis.
Log Collector:
zbiera, parsuje, zapisuje logi, dodaje dodatkowe atrybuty jak geolokalizacje, zapisuje do elasticsearch na podstawie IP z którego pochodzą logi
Full text search engine:
elasticsearch, logi zapisywane w formacie JSON, indeksy replikowane i shardowane, partycjonowane względem czasu, usuwanie starych wpisów na podstawie daty
konfiguracja - Marvel plugin
GUI:
Kibana 3
ANDRZEJ GRZESIKGo, go, go - the one language to try in 2014. (or: "write only an eight of the code" ;-))
GO to język ułatwiający programowanie aplikacji wielowątkowych, coś jak mix C++ z Ruby, nie ma zależności w runtime od bibliotek systemu (biblioteki łączone statycznie). Ponoć Andrzej brał udział w przepisaniu apki Springowej na GO, dzięki czemu zredukował ilość linii kodu do 1/8 początkowej ilości.
Chciałbym zobaczyć jak wygląda taka apka. Andrzej pokazał proste konstrukcje języka, ciekawe cechy:
- GO narzeka jeśli jakieś importy nie są używane, nie pozwala skompilować kodu
- brak wyjątków, zamiast tego są kody błędu
- formater kodu wbudowany w interpreter ("go fmt")
Miała być to zachęta do spróbowania języka samemu.
TOMASZ BARANSKILockless programming
Wstęp do tego jak programować współbieżnie nie używając semaforów, zamiast tego mechanizmów takich jak:
- operacje atomowe (Compar And Swap, Fetch and Add, Add And Fetch)
- memory barriers - wymuszać na kompilatorze, żeby nie optymalizował naszego kodu i nie zmieniał kolejności instrukcji read/write zmiennych (Read Read Barrier, Store Store Barrier) np:
przed kompilacja:
read X
barrier
read Y
po kompilacji:
read X
read Y
Rozwiązania dostępne w Javie:
AtomicInteger
AtomicReference
AtomicStampedReference
AtomicIntegerArray
Przyznaje bez bicia ze trochę odpłynąłem na tym wykładzie, nie wszystko było dla mnie jasne i dawno nie wchodziłem w tak niskopoziomowe programowanie, nie miałem tez takiej potrzeby projektowej.
ADAM DUDCZAKJUnit: beyond the basics
Wiele pożytecznych sztuczek w pisaniu testów JUnit
- https://code.google.com/p/junitparams/
- org.junit.experimential.theories
- randomized unit testing
- @Rule - reusable @Before/@After
- mocking external services:
co.freeside.betamax.*
WireMock
- JUnit Benchmarks
- expected exception rule
- nowe "assertions": Hamcrest, Fest / AssertJ
- organizowanie testow w @Suite, w kolejnych wersjach JUnit zamienione na @Category
Prezentacja dostępna na: https://bitbucket.org/maneo/junit-presentation
JAMIE WINSORChef Development and Release Patterns for Software Engineers
Jamie na GitHubie: https://github.com/reset
Termin "deploy window" to jasny wyznacznik tego, że system buildów nie działa poprawnie.
Deploy powinien móć być robiony bez obaw w każdej chwili poprzez kliknięcie jednego przycisku :)
Zasady powinny być takie:
- automatyzuj i testuj co tylko się da
- wersjonuj, pakuj i wypuszczaj wszystko (kod, DB)
- wbuduj deployment w build process
- buduj nawet serwer buildow (z użyciem np Valgrant)
Toolbox:
- Elixir - jezyk na bazie Erlanga
- Chef Deployment Kit
- Berkshelf
- KitchenCI
Na konferencji można było tez spotkać ludzi z Octawave, porozmawiać o ich serwisach w chmurze oraz dowiedzieć się jak wygląda rekrutacja w Allegro (głównego sponsora konferencji).
Drugiego dnia między prezentacjami można było też pooglądać w salach kinowych wywiadów z prelegentami -w sumie ciekawa opcja, nie spotkałem się z czymś takim na innych konferencjach.
Mam nadzieje ze niczego nie przekłamałem, a jeśli tak to proszę mnie poprawić :)
Ponoć czasy kiedy człowiek z działu Operations nigdy nie tykał się tego co Development i odwrotnie, dawno już minęły i w obliczu szybko zmieniających się technologii i konkurencji na rynku rzadko kiedy odpowiedzialności są tak podzielone.
Konferencja moim zdaniem ciekawa, chociaż nie wiem czy warta wpisowego, które w wersji 'last-minute' sięgnęło astronomicznej kwoty 1000 PLN ! Ja byłem tym szczęściarzem, któremu Michał Bartyzel udostępnił wejściówkę za darmo.
Faktem jest że organizacja konferencji była na bardzo wysokim poziomie.
Tak wyglądały przygotowania:
Super miejsce z dobrze przystosowanym audio/wideo (oczywista sprawa, gdyż było to kino), no i ciekawe tematy (2 ścieżki). Prawdopodobnie niebawem ukażą się nagrania na youtube. Na razie są tylko z poprzedniej edycji tutaj.
Zanim się ukażą postaram się kilka z nich streścić:
Dzien 1
PHIL DIBOWITZScaling systems configuration at Facebook: the paradigms, design, and software behind managing massive numbers of systems with open source and small teams
Troche o prelegencie:
Przedstawił następujące problemy w swoim teamie:
- support wielu konfiguracji z rożnych projektów
- ok. 100 000 serwerów do utrzymania
- brak centralnego miejsca przetrzymywania konfiguracji klastra
- jedna domyślna konfiguracja nadpisywana per projekt
- wiele niewielkich zespołów, każdy wprowadza swoje zmiany
- duża nadmiarowość: cześć wspólna się nie zmienia i zaciemnia wgląd w to co konkretnie się zmieniło w projekcie.
Celem było dojście do stanu gdy 4 osoby mogą utrzymać 100 000 serwerów.
Brali pod uwagę rożne narzędzia: Puppet, Chef, Spine.
W końcu wybrali Chef. Powodem była jego łatwa rozszerzalność i adaptacja do workflowu.
Osiągnęli:
- usuniecie wielu zduplikowanych plików konfiguracyjnych
- usuniecie nieużywanych settings
- stworzyli domyślną konfiguracje nadpisywaną potem w Ruby specyficznymi ustawieniami
Architektura wygląda tak, ąe jest serwer tzw. Service of Reference (SOR), który trzyma rekord węzłów w klastrze. Serwery Chef są bezstanowe, nic nie wiedza o istniejących węzłach.
Na węzłach jest zainstalowany Ohai plugin i podłączony do konkretnego SOR.
Handlery do raportów monitorują instalacje. Konfiguracje są trzymane w SVN.
Przykład:
Stworzyli tez zestaw własnych narzędzi dostępnych na githubie.
Ciekawie zapowiada się jeden z nich: test-tester - ponoć umożliwia testowanie konfiguracji bezpośrednio na serwerach produkcyjnych nie powodując dla nich zagrożenia w przypadku błędów (do końca nie zrozumiałem jak to działa).
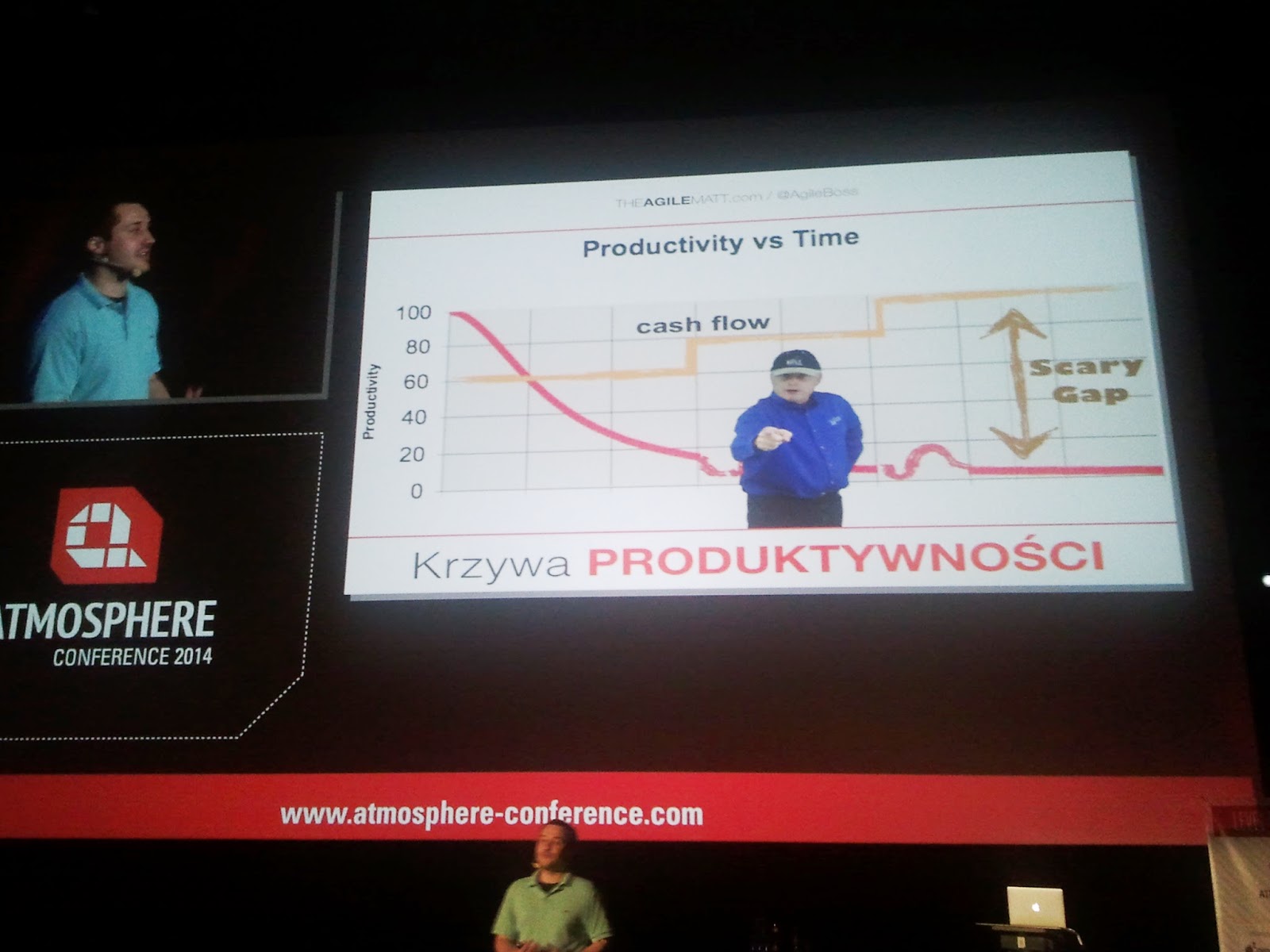
DANIEL TOROKOur Continuous Delivery Pipeline
Daniel pracuje w Prezi
Przedstawił w jaki sposób ewoluował ich system Continuous Delivery.
Oto moje niezdarne schematy w poszczególnych fazach :) byłyby lepsze, gdyby nie jakość zdjęć z telefonu nie nadających się do niczego.
1. Każdy node monitoruje wersje uploadowaną na Amazon S3 z zainstalowaną u siebie i jeśli się zmieniła do ściąga i instaluje
Minusy: trudność w monitorowaniu procesu i utrzymaniu: każdy node konfigurowany ręcznie.
2. Dodano Zookeeper do zarządzania konfiguracjami i mission control do monitorowania
3. Lepszy monitoring Inciga (każda aplikacja ma swój health endpoint, który jest co jakiś czas sprawdzany) i parsowanie logów w Logster. Następnie statystyki są przedstawiane real-time na diagramach z użyciem Graphite i służą do analizy instalacji a także w przypadku gdy coś się wywali na produkcji.
MAXIMILIANO FIRTMANThe mobile web challenges
Maximiliano jest autorem bloga http://www.mobilexweb.com/ na oraz prowadzi ranking kompatybilności przeglądarek http://mobilehtml5.org/
Developmnet aplikacji mobilnych to prawdziwa dżungla, biorąc pod uwagę różne typy aplikacji:
- natywne
- webowe
- hybrydowe
oraz mnogość urządzeń
W przypadku aplikacji webowych mamy też mnogość przeglądarek, których popularność różni się od regionu geograficznego. Z ciekawostek - rejon Indie, Pakistan, Bangladesz używa najczęściej (98%?) przeglądarki UC Browser, o której słyszałem pierwszy raz.
Nie ma jednej słusznej zasady tworzenia aplikacji mobilnych, wszystko zależy od zastosowania i docelowych użytkowników. Zawsze najważniejsza jest percepcja użytkownika, np czy użytkownikowi wydaje się że aplikacja działa wolno, czy nie. Niektóre ograniczenia urządzeń mobilnych, jak np. słabą przepustowość łącza, można zminimalizować:
- ładując zasoby, np grafikę w tle
- pre-renderując HTML po stronie serwera w zależności od rodzaju urządzenia, języka, wielkości ekranu itd.
Inne ważne zasady:
- nie frustruj użytkownika (np przy logowaniu z użyciem sieci społecznościowych nie wymagaj dostępu do wszystkich danych użytkownika jeśli tego nie potrzebujesz)
- wydajność aplikacji jako główny cel (tworzenie stron tzw. responsywnych, które dobrze renderują się na urządzeniach mobilnych ale przy okazji zasysają ogromne ilości CSS i JS to nie zawsze najlepszy pomysł, szczególnie gdy docelowa grupa prawie nigdy nie używa desktopów).
Jeśli chodzi o narzędzia i testowanie też nie jest łatwo. W zależności od platformy mamy do dyspozycji symulatory, emulatory lub urządzenie fizyczne.
Są tez strony gdzie możemy przetestować jak nasza aplikacja zachowa się na różnych urządzeniach, np.
http://developer.samsung.com/remotetestlab
Kilka wskazówek jak być przygotowanym na przyszłość i to w jakim kierunku rozwija się mobile dev.:
- technologie "push" - push z serwera na klienta
- detekcja dostępnych funkcji urządzenia (GPS, akcelerometr, itd.) i dostosowanie zachowania aplikacji do nich
- synchronizacja - śmieszny przykład jaki dał Maximiliano to gdy w środku nocy w pokoju, w którym trzyma kilkanaście różnych urządzeń mobilnych dostaje e-maila i każde z tych urządzeń dostaje "push" - nagle jego pokój zamienia się w wesołe miasteczko, wszystko gra i świeci :D
Użytkownik powinien mieć możliwość wyboru co chce na danym urządzeniu synchronizować, np gdy tableta używa do czytania prasy, książek, a telefonu do sprawdzania poczty.
Inne metodologie o których nie słyszałem wcześniej:
- RESS (Responsive Design with Server-Side components) to sposób tworzenia aplikacji klient-serwer, w którym pomiędzy klienta i serwer daje się jeszcze jedną warstwę pośrednią służącą poprawę wydajności na kliencie (np dostosowanie rozmiaru grafik do ekranu urządzenia, dostosowanie HTML, CSS, JS)
ADAM MICHALCZYKEverybody lies
Adam z Allegro zastanawiał się dlaczego ludzie kłamią, niezależnie od swojej roli w projekcie: czy to Developerzy, Product Ownerzy, Operations..
Powody bywają różne, jak:
- wygodnictwo
- wzajemne niezrozumienie
- opieranie się na opiniach, nie faktach
- strach przed konsekwencjami
Adam jest propagatorem kultury pracy, w której nie boimy się popełnić błędy o ile są one bezpieczne ("safe to fail" a nie "failsafe"), tzn istnieje cały mechanizm zabezpieczający przed tym by błędy nie były kosztowne i wychwycone wcześnie (jak np continuous integration z testami aplikacji). Powołuje się na książkę Joy Inc.
Kultura pracy nie powinna piętnować popełnianych błędów, wręcz przeciwnie - zachęcać do eksperymentowania i otwartości.
SZYMON PRZYBYLSKIOptimising and Automating your Front End Workflow
Jakich narzędzi powinien dziś używać front-end developer by ułatwić sobie życie?
Apki JavaScript-owe bardzo ewoluowały w przeciągu ostatnich kilkunastu lat. To już nie tylko język który upycha się gdzieś w stronę JSP ale pozwalający tworzyć kompletne aplikacje po stronie klienta i serwera. Narzędzia godne poznania to:
- npm
- bower
- grunt
- gulp
- walidatory: JSLint, JSHint, ESLint
- frameworki do testowania: Jasmine, Mocha, QUnit
KRZYSZTOF DEBSKILet's build a solid base for a scale.
Krzysiek pracuje w Allegro, które obchodzi w tym roku 15 rocznicę powstania. Od czasu, gdy powstało przeszło sporą ewolucję technologiczną od homogenicznego sytemu do skalowalnego w chmurze z 15 mln. użytkowników.
Obecnie architektura opiera się na mikro-serwisach komunikujących się ze sobą rożnymi API (REST, SOAP, CORBA..) Modernizacja trwa. W grę wchodzą takie technologie jak:
Zookeeper - jako rejestr serwisów
Swagger - biblioteka do generacji dokumentacji dla serwisów REST, dostepne także Swager UI, całkiem przyjemna strona HTML do wizualizacji dokumentacji.
Do tworzenia REST API używany jest Jersey, wersjonowanie REST API za pomocą HTTP nagłówka Accept.
Konfiguracja serwisu kilkustopniowa:
- Zookeeper
- zmienne środowiskowe
- argumenty linii komend
Początkowo serwisy były bootstrapowane w zewnętrznym Jetty ale działało to zbyt wolno, stąd przejście na embedded Jetty a potem na embedded Undertow. Dzięki temu każdy serwis jest samodzielny, nie potrzeba go deployować na serwerze.
Monitoring z użyciem:
- Logstash
- Kibana
- NxLog
- Graphite
Obecnie trwają eksperymenty z użyciem Dockera.
MaTeusz HarasymczukRE:SPONSIBILITY.
Ten wykład był poprowadzony w zastępstwie za Andy Hawkinsa.
Mateusz zastanawiał się nad tym po co skupiać się na poprawie jakości istniejących rozwiązań skoro klient za to nie płaci tylko za nowe funkcjonalności. Otóż warto, bo to właśnie utrzymanie kosztuje najwięcej.
Przy przejrzystym i prostym kodzie z małą liczbą zależności utrzymanie to przyjemność a jakiekolwiek zmiany są szybkie do implementacji.
Każdy powinien być zawsze odpowiedzialny za swój kod, nawet po tym gdy kod już trafi na produkcję.
Wyobraź sobie że Twój kod jest użyty do obsługi przyrządów w samolocie, którym właśnie poleci Twoje dziecko, czy wpuściłbyś je spokojnie na pokład?
Źródło informacji o security w node.js: https://nodesecurity.io/
Aplikacje node.js działają blisko systemu operacyjnego przez co narażone na wiele błędów związanych z bezpieczeństwem.
Co więcej, mnogość bibliotek pisanych często bez nadzoru zewnętrznej instytucji pozwala przecieknąć do naszej aplikacji potencjalnie niebezpiecznym kodom, dlatego zewnętrzne kody co do których nie jesteśmy pewni powinny być przeskanowane pod kątem użycia niebezpiecznych konstrukcji takich jak:
- eval(code)
- setInterval(code, ..)
- setTimeout(code,..)
- str = new Function(code)
- global namespace polution - gdy wszystkie zmienne w kodzie serwerowym są wspólne dla wszystkich klientów, należy o tym pamiętać, że w aplikacjach node.js wszyscy klienci używają jednej metody serwerowej, która działa w jednym wątku, dlatego też współdzielą jej zmienne.
Przykładowy błąd:
Gdy jeden klient zostaje zautentykowany, zapisujemy w globalnej zmiennej, że ma dostęp do zasobów.
Następnie serwer obsługuje request innego klienta, który jeszcze się nie logował ale ponieważ stan został zmieniony przez poprzedniego klienta, ten drugi może bezprawnie dostać się do zasobów chronionych.
- niełapane wyjątki powodujące wywalenie się głównej metody serwera i tym samym stopujące serwer (teraz już po konferencji wertując sieć natknąłem się na taką stronkę o wyjątkach w node.js)
Metody prewencji:
- strict mode ("use strict;"), również dla dołączanych bibliotek - dzięki temu parser wychwyci wszystkie metody, w których przekazywane mogą być komendy systemowe w stringu.
- JSHint (node-jshint), JSLint (node-jslint
- statyczne analizatory kodu
- retire.js
- użycie gotowych modułów do autentykacji zamiast pisać ręcznie i narażać się na błedy, np passportjs
- express-domain-middleware
- sandboxing - proces nodejs nie jest uruchamiany bezpośrednio w systemie operacyjnym ale w chronionym środowisku, które nie ma dostępu np do prawdziwego systemu plików, czyli wirtualizacja, np: SELinux Sandbox
Dzien 2
MICHAL CZAPRACKIScalability and Websockets: Creating a Websocket CDN with DIASP.
Zalety websocket:
- ciągła komunikacja
- komunikacja dwukierunkowa
- zabiera małą część łącza
- wiele bibliotek implementujących
Wady websocket:
- wiele jednocześnie otwartych połączeń
- trudne do implementacji w standardowych frameworkach
- niekompatybilne z większością proxy (np Varnish, Squid)
- brak warstwy cache
Michał brał udział w tworzeniu rozwiązania opartego na websocketach dla gazera.pl web i sport.pl web (obie około 2mln ściągnięć na urządzeniach mobilnych). Z powodu ograniczeń standardowych bibliotek websocket musieli napisać własne rozwiązanie które pozwalało na cachowanie, tzw DIASP (Diasp Is a Socket Proxy)
Testy pokazały że jest ono w stanie obsłużyć 20 000 jednoczesnych połączeń na maszynie z 300MB RAM
W dniu prezentacji rozwiązanie zostało OpenSource-owane na
https://github.com/AgoraTech/diasp
MACIEJ KUZNIARSwitching from monolithic approach to modular cloud computing, within the context of providing high availability application
Maciej opowiedział z grubsza o serwisach dostarczanych przez Octawave, czyli generalnie wszystko o czym można poczytać na https://www.oktawave.com/pl/instancje-chmury.html
DARIUSZ ELIASZCentralized log management based on Logstash and Kibana - case study.
I znów pojawiają się znajome nazwy (na razie jedynie nazwy bo nie próbowałem tego jeszcze).
Darek opowiedział o swojej drodze do stworzenia systemu zarządzania logami i monitoringu aplikacji.
Pierwszy etap to wybór właściwego protokołu komunikacji. Rozważane opcje:
- RFC 3164 - limitowany do 1KB, stały format, niezbyt elastyczny
- JSON - lekki, elastyczny, bez limitu co do formatu, duże wsparcie istniejących bibliotek i narzędzi
Architektura zbierania logów:
wiele interfejsów wejściowych (ftp, tcp, udp socket), wiele rodzajów parserów (BSD log, JSON)
jak najwięcej się da przetwarzania logów robi Sender zanim pości je dalej.
W pierwszej wersji użyty był NxLog, potem zastąpiony syslog-ng
Log Router:
w pierwszej wersji Logstash + Redis, potem tylko Redis.
Log Collector:
zbiera, parsuje, zapisuje logi, dodaje dodatkowe atrybuty jak geolokalizacje, zapisuje do elasticsearch na podstawie IP z którego pochodzą logi
Full text search engine:
elasticsearch, logi zapisywane w formacie JSON, indeksy replikowane i shardowane, partycjonowane względem czasu, usuwanie starych wpisów na podstawie daty
konfiguracja - Marvel plugin
GUI:
Kibana 3
ANDRZEJ GRZESIKGo, go, go - the one language to try in 2014. (or: "write only an eight of the code" ;-))
GO to język ułatwiający programowanie aplikacji wielowątkowych, coś jak mix C++ z Ruby, nie ma zależności w runtime od bibliotek systemu (biblioteki łączone statycznie). Ponoć Andrzej brał udział w przepisaniu apki Springowej na GO, dzięki czemu zredukował ilość linii kodu do 1/8 początkowej ilości.
Chciałbym zobaczyć jak wygląda taka apka. Andrzej pokazał proste konstrukcje języka, ciekawe cechy:
- GO narzeka jeśli jakieś importy nie są używane, nie pozwala skompilować kodu
- brak wyjątków, zamiast tego są kody błędu
- formater kodu wbudowany w interpreter ("go fmt")
Miała być to zachęta do spróbowania języka samemu.
TOMASZ BARANSKILockless programming
Wstęp do tego jak programować współbieżnie nie używając semaforów, zamiast tego mechanizmów takich jak:
- operacje atomowe (Compar And Swap, Fetch and Add, Add And Fetch)
- memory barriers - wymuszać na kompilatorze, żeby nie optymalizował naszego kodu i nie zmieniał kolejności instrukcji read/write zmiennych (Read Read Barrier, Store Store Barrier) np:
przed kompilacja:
read X
barrier
read Y
po kompilacji:
read X
read Y
Rozwiązania dostępne w Javie:
AtomicInteger
AtomicReference
AtomicStampedReference
AtomicIntegerArray
Przyznaje bez bicia ze trochę odpłynąłem na tym wykładzie, nie wszystko było dla mnie jasne i dawno nie wchodziłem w tak niskopoziomowe programowanie, nie miałem tez takiej potrzeby projektowej.
ADAM DUDCZAKJUnit: beyond the basics
Wiele pożytecznych sztuczek w pisaniu testów JUnit
- https://code.google.com/p/junitparams/
- org.junit.experimential.theories
- randomized unit testing
- @Rule - reusable @Before/@After
- mocking external services:
co.freeside.betamax.*
WireMock
- JUnit Benchmarks
- expected exception rule
- nowe "assertions": Hamcrest, Fest / AssertJ
- organizowanie testow w @Suite, w kolejnych wersjach JUnit zamienione na @Category
Prezentacja dostępna na: https://bitbucket.org/maneo/junit-presentation
JAMIE WINSORChef Development and Release Patterns for Software Engineers
Jamie na GitHubie: https://github.com/reset
Termin "deploy window" to jasny wyznacznik tego, że system buildów nie działa poprawnie.
Deploy powinien móć być robiony bez obaw w każdej chwili poprzez kliknięcie jednego przycisku :)
Zasady powinny być takie:
- automatyzuj i testuj co tylko się da
- wersjonuj, pakuj i wypuszczaj wszystko (kod, DB)
- wbuduj deployment w build process
- buduj nawet serwer buildow (z użyciem np Valgrant)
Toolbox:
- Elixir - jezyk na bazie Erlanga
- Chef Deployment Kit
- Berkshelf
- KitchenCI
Na konferencji można było tez spotkać ludzi z Octawave, porozmawiać o ich serwisach w chmurze oraz dowiedzieć się jak wygląda rekrutacja w Allegro (głównego sponsora konferencji).
Drugiego dnia między prezentacjami można było też pooglądać w salach kinowych wywiadów z prelegentami -w sumie ciekawa opcja, nie spotkałem się z czymś takim na innych konferencjach.
Mam nadzieje ze niczego nie przekłamałem, a jeśli tak to proszę mnie poprawić :)
super post - dzieki za takie streszczenie
OdpowiedzUsuńtak fajny post - szkoda ze nas tam nie bylo :)
OdpowiedzUsuńTeż zazdroszę, tyle ciekawych tematów.
OdpowiedzUsuńJuz mozna sie rejestrowac na konferencje za rok - jedyne 599 NETTO :D
OdpowiedzUsuń